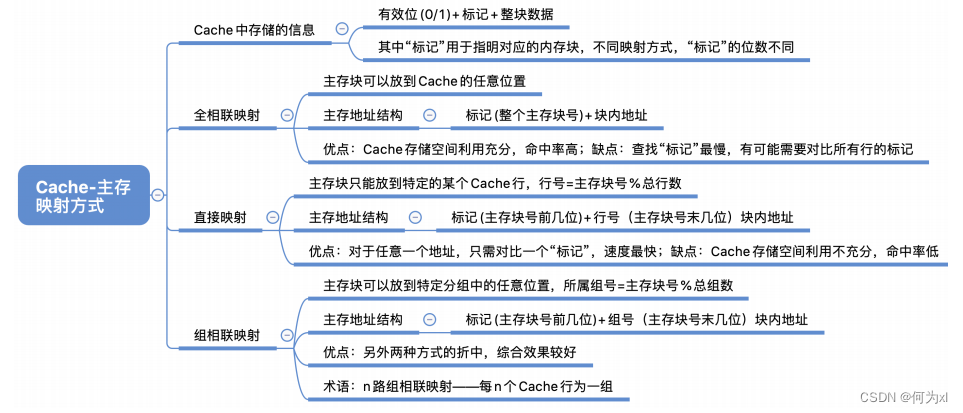
一、Cache - 主存的映射方式
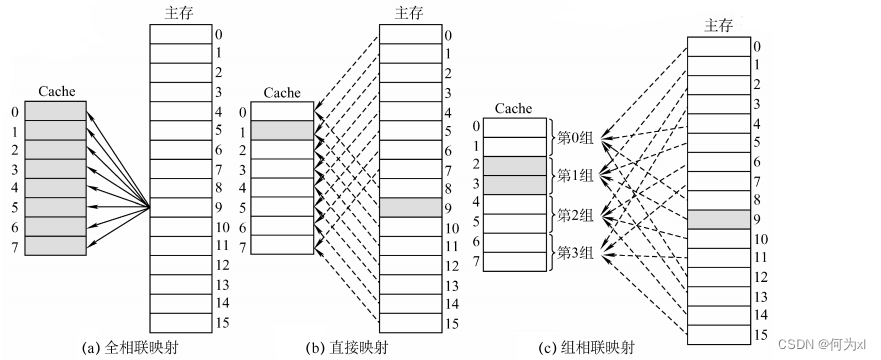
全相联映射:主存块可以放在 Cache 的任意位置。
直接映射:每个主存块只能放到一个特定的位置:
Cache块号 = 主存块号 % Cache总块数
组相联映射:Cache块分为若干组,每个主存块可放到特定分组中的任意一个位置: 组号 = 主存块号 % 分组数
(一)、全相联映射(随意放)
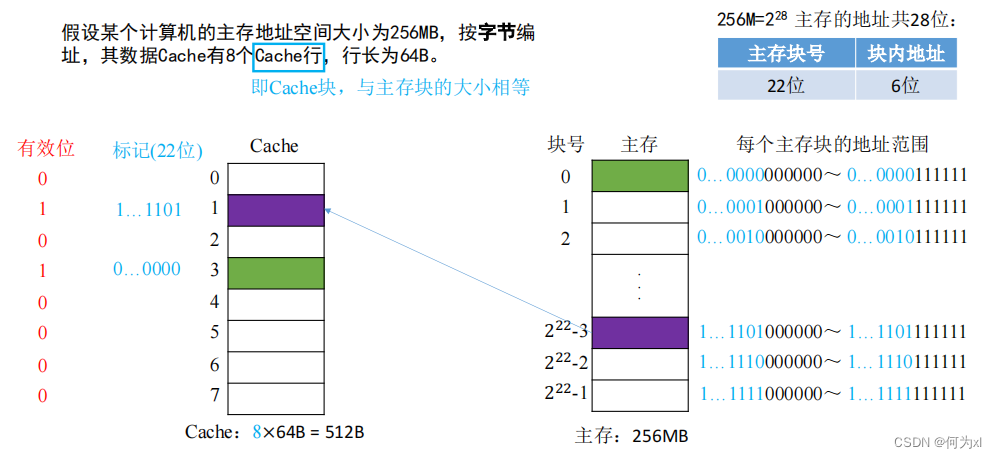
CPU 访问主存地址 1…1101001110:
①主存地址的前22位,对比Cache中所有块的标记;
②若标记匹配且有效位=1,则Cache命中,访问块内地址为 001110 的单元。
③若未命中或有效位 = 0,则正常访问主存。
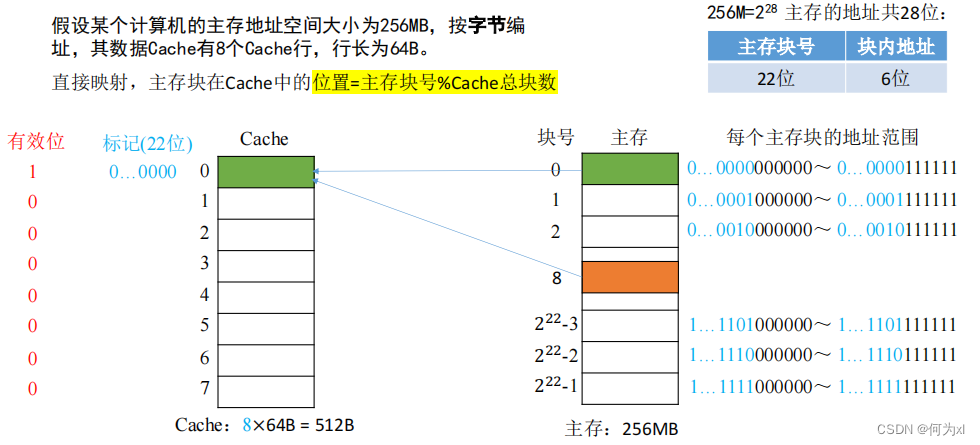
(二)、直接映射(只能放固定位置)
直接映射,主存块在Cache中的位置 = 主存块号 % Cache总块数。
若 Cache总块数 = 2 n 2^n2n 则主存块号末尾n位直接反映它在Cache 中的位置。将主存块号的其余位作为标记即可。
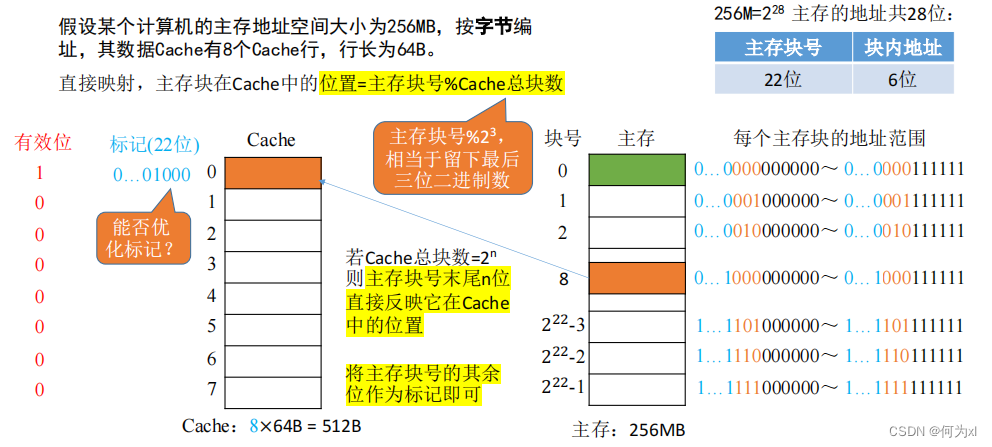
此时主存地址为:
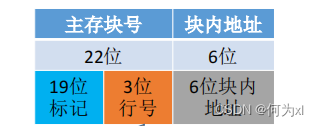
CPU 访问主存地址 0…01000 001110 :
①根据主存块号的后 3位确定Cache行 。
②若主存块号的前 19 位与Cache标记匹配且有效位=1,则Cache命中,访问块内地址为 001110 的单元。
③若未命中或有效位=0,则正常访问主存。
(三)、组相联映射(可放到特定分组)
n 路组相联映射 —— n块为一组
eg:2路组相联映射——2块为一组
组相联映射,所属分组 = 主存块号 %分组数
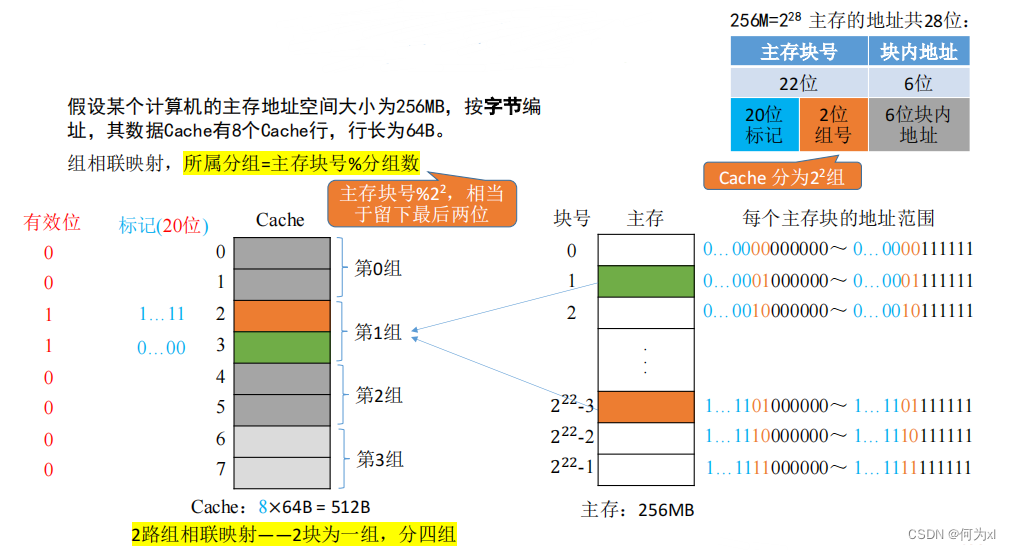
CPU 访问主存地址1…1101001110 :
①根据主存块号的后 2位确定所属分组号。
②若主存块号的前20位与分组内的某个标记匹配且有位=1, 则Cache命中,访问块内地址为 001110的单元。
③若未命中或有效位=0,则正常访问主存。
(四)Cache - 主存的映射方式总结
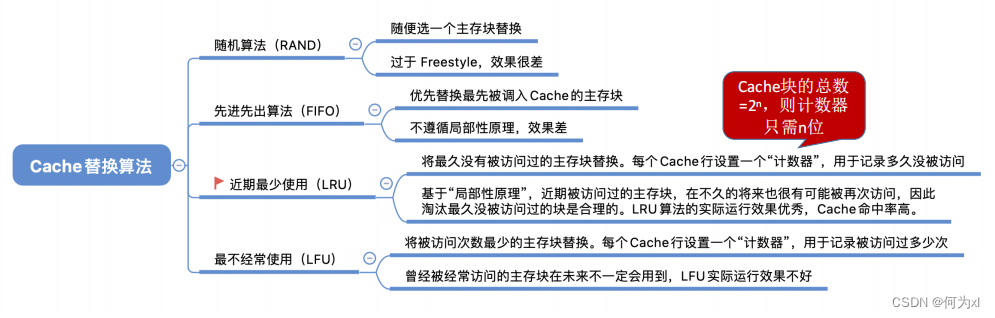
二、Cache 替换算法
前面介绍了 Cache 与主存的映射,说明了 Cache块映射到主存块的位置。但是未说明当 Cache 内存满了时应该选择哪个 Cache 进行替换,这当中涉及到 Cache 替换算法。
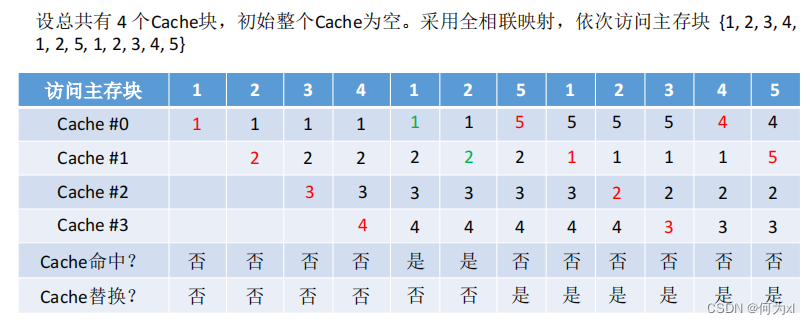
(一)、随机算法(RAND)
随机算法(RAND, Random)——若Cache已满,则随机选择一块替换。
随机算法——实现简单,但完全没考虑局部性原理,命中率低,实际效果很不稳定。
(二)、先进先出算法(FIFO)
先进先出算法(FIFO, First In First Out)—— 若Cache已满,则替换最先被调入Cache 的块。
先进先出算法 —— 实现简单,最开始按#0#1#2#3放入Cache,之后轮流替换 #0#1#2#3 。FIFO依然没考虑局部性原理,最先被调入Cache的块也有可能是被频繁访问的。
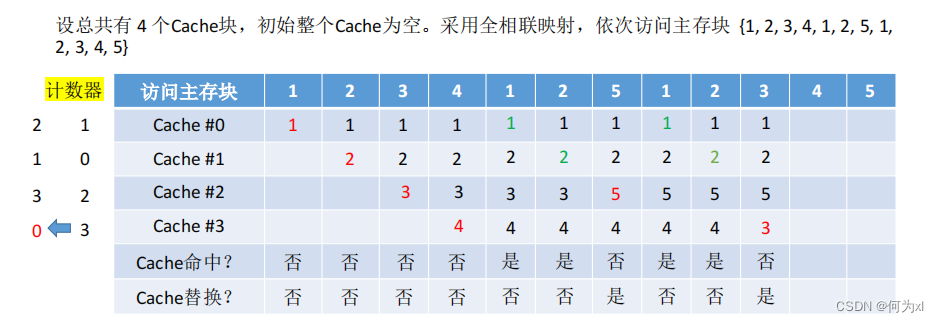
(三)、近期最少使用算法(LRU)
近期最少使用算法(LRU, Least Recently Used )—— 为每一个Cache块设置一个“计数器”,用于记录每个 Cache 块已经有多久没被访问了。当 Cache 满后替换“计数器”最大的。
①命中时,所命中的行的计数器清零,比其低的计数器加1,其余不变;
②未命中且还有空闲行时,新装入的行的计数器置0,其余非空闲行全加1;
③未命中且无空闲行时,计数值最大的行的信息块被淘汰,新装行的块的计数器置0,其余全加1。
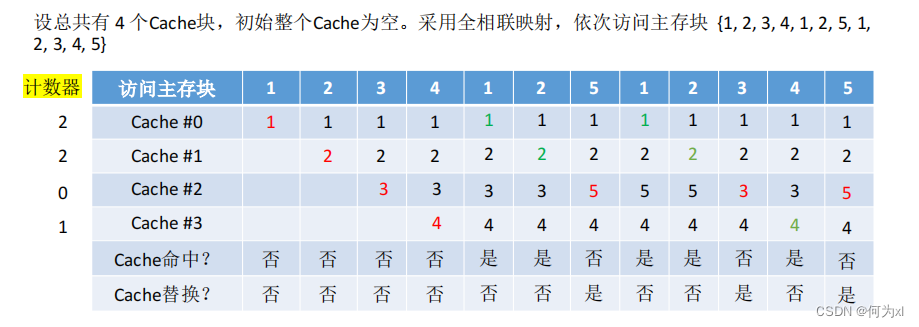
(四)、最不经常使用算法(LFU)
最不经常使用算法(LFU, Least Frequently Used )—— 为每一个Cache块设置一个“计数器”,用于记录每个Cache块被访问过几次。当Cache满后替换“计数器”最小的。
新调入的块计数器=0,之后每被访问一次计数器+1。需要替换时,选择计数器最小的一行。
(五)、Cache 替换算法的总结
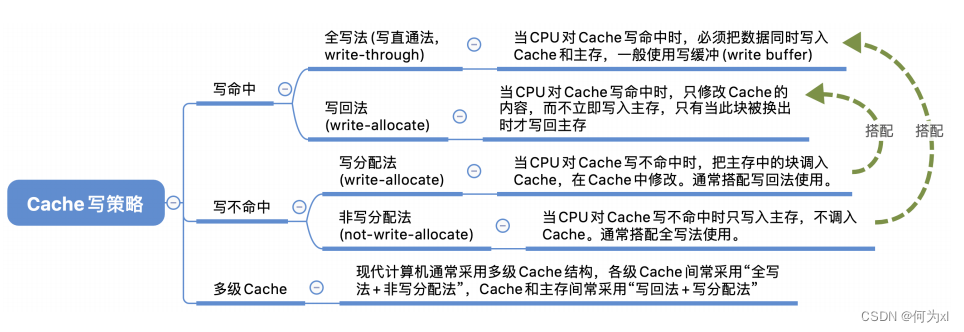
三、Cache 写策略
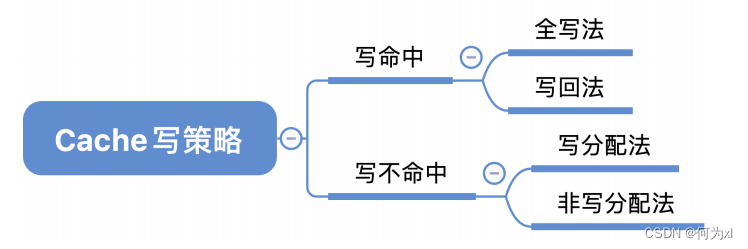
(一)、写命中
1. 写回法
写回法(write-back) —— 当CPU对Cache写命中时,只修改Cache的内容,而不立即写入主存,只有当此块被换出时才写回主存。
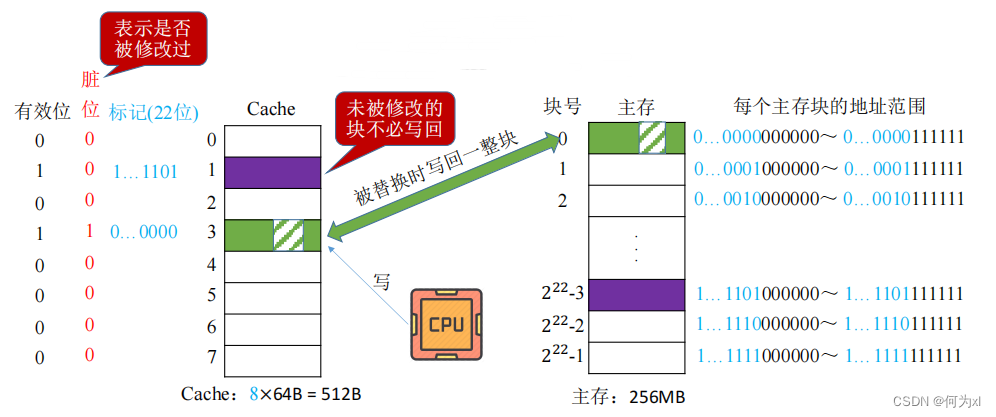
减少了访存次数,但存在数据不一致的隐患。
2. 全写法
全写法(写直通法,write-through) —— 当CPU对Cache写命中时,必须把数据同时写入 Cache 和主存,一般使用写缓冲(write buffer)。使用写缓冲,CPU写的速度很快,若写操作不频繁,则效果很好。若写操作很频繁,可能会因为写缓冲饱和而发生阻塞。
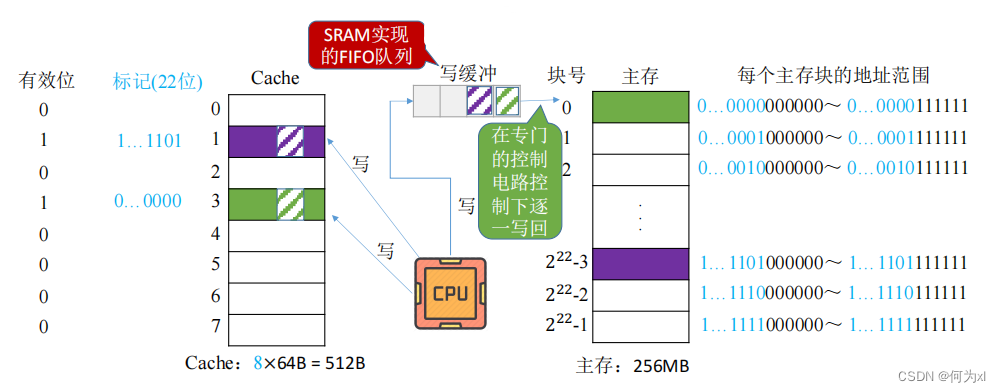
访存次数增加,速度变慢,但更能保证数据一致性。Cache块被替换时无需写回。
(二)、写不命中
1. 写分配法
写不命中时,把主存中的块调入Cache,在Cache中修改。
搭配写回法使用。
写回法(write-back) —— 当CPU对Cache写命中时,只修改Cache 的内容,而不立即写入主存,只有当此块被换出时才写回主存。
2. 非写分配法
非写分配法(not-write-allocate)——当 CPU 对 Cache 写不命中时只写入主存,不调入Cache。搭配全写法使用。
全写法(写直通法,write-through) —— 当 CPU 对 Cache 写命中时,必须把数据同时写入Cache 和主存,一般使用写缓冲(write buffer)。
(三)、多级Cache
现代计算机常采用多级Cache,离CPU越近的速度越快,容量越小,离CPU越远的速度越慢,容量越大。
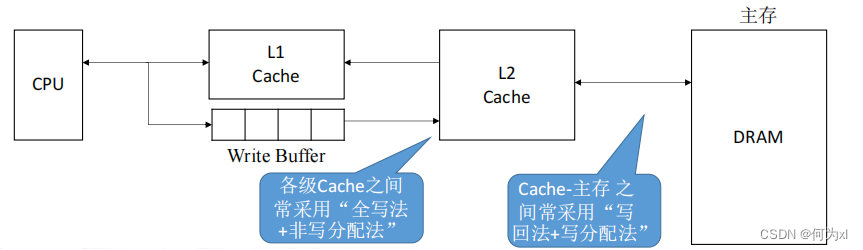
(四)、Cache 写策略的总结
链接:https://blog.csdn.net/weixin_43848614/article/details/126822596
作者:何为xl